Quora Duplicate Questions
This folder contains scripts that demonstrate how to train SentenceTransformers for Information Retrieval. As a simple example, we will use the Quora Duplicate Questions dataset. It contains over 500,000 sentences with over 400,000 pairwise annotations whether two questions are a duplicate or not.
Models trained on this dataset can be used for mining duplicate questions, i.e., given a large set of sentences (in this case questions), identify all pairs that are duplicates. Due to how CrossEncoder models work only on pairs of texts, they are best deployed after an initial filtering using a SentenceTransformer model. See Sentence Transformer > Usage > Paraphrase Mining for an example how to use sentence transformers to mine for duplicate questions / paraphrases across hundred thousands of sentences.
After the initial filtering, a CrossEncoder model can be used to rerank the top e.g. 100 candidates into the top e.g. 10. Because a CrossEncoder can apply attention across the sentences from the pairs, the model can give better scores than the SentenceTransformer can.
To train a CrossEncoder on the Quora Duplicate Questions dataset, see the following example file:
training_quora_duplicate_questions.py:
This example uses
BinaryCrossEntropyLossto train the CrossEncoder model to give high scores for identical questions and low scores for different questions.
You can also train and use SentenceTransformer models for this task. See Sentence Transformer > Training Examples > Quora Duplicate Questions for more details.
Training
Choosing the right loss function is crucial for finetuning useful models. BinaryCrossEntropyLoss remains a very solid loss for training any CrossEncoder model that has just one output class, i.e. if it just outputs one score.
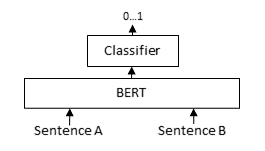
For each question pair, we pass question A and question B through the BERT-based model, after which a classifier head converts the intermediary representation from the BERT-based model into a similarity score. With this loss, we apply torch.nn.BCEWithLogitsLoss which accepts logits (a.k.a. outputs, raw predictions) and gold similarity scores (1 if duplicate, 0 if not duplicate) to compute a loss denoting how well the model has done. This loss is then minimized to improve the performance of the model.
Inference
You can perform inference using any of the pre-trained CrossEncoder models for Duplicate Question detection like so:
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/quora-distilroberta-base')
scores = model.predict([
('What do apples consist of?', 'What are in Apple devices?'),
('How do I get good at programming?', 'How to become a good programmer?')
])
print(scores)
# [0.00056, 0.97536]