Speeding up Inference
See also
This page focuses on backend-level optimizations (ONNX, OpenVINO, model quantization). For complementary techniques that reduce storage and search cost at the embedding level, see the Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval blogpost (post-training compression of output vectors), the 🪆 Introduction to Matryoshka Embedding Models blogpost (truncatable embeddings), and the Train 400x faster Static Embedding Models blogpost (attention-free CPU-friendly models).
Sentence Transformers supports 3 backends for computing embeddings, each with its own optimizations for speeding up inference:
PyTorch
The PyTorch backend is the default backend for Sentence Transformers. If you don’t specify a device, it will use the strongest available option across “cuda”, “mps”, and “cpu”. Its default usage looks like this:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
If you’re using a GPU, then you can use the following options to speed up your inference:
Float32 (fp32, full precision) is the default floating-point format in torch, whereas float16 (fp16, half precision) is a reduced-precision floating-point format that can speed up inference on GPUs at a minimal loss of model accuracy. To use it, you can specify the torch_dtype during initialization or call model.half() on the initialized model:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", model_kwargs={"torch_dtype": "float16"})
# or: model.half()
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
Bfloat16 (bf16) is similar to fp16, but preserves more of the original accuracy of fp32. To use it, you can specify the torch_dtype during initialization or call model.bfloat16() on the initialized model:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", model_kwargs={"torch_dtype": "bfloat16"})
# or: model.bfloat16()
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
Flash Attention is an efficient attention implementation that can significantly speed up inference on GPUs. When flash attention with variable-length support is available, Sentence Transformers automatically skips padding for text-only inputs by concatenating them into a single sequence. This eliminates the overhead of padding shorter texts to the longest text in the batch, which is especially beneficial when input lengths vary widely.
To use flash attention, specify attn_implementation="flash_attention_2" in model_kwargs. Flash attention can be installed
via pip install kernels, which provides flash attention support without needing the flash-attn package, or alternatively
via pip install flash-attn:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"attn_implementation": "flash_attention_2", "torch_dtype": "bfloat16"},
)
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
Note
Automatic input unpadding requires transformers >= 5.0.0 and is enabled by default when flash attention
with variable-length support is installed and compatible with the model architecture. You can control this
via unpad_inputs on the underlying
Transformer module:
model[0].unpad_inputs = False # Force padding (e.g. for architectures that don't support unpadded inputs)
model[0].unpad_inputs = True # Explicitly request unpadding
model[0].unpad_inputs = None # Auto-detect (default)
The following benchmark compares throughput and VRAM usage across three attention configurations using BAAI/bge-base-en-v1.5, averaged across batch sizes. Four datasets with varying text lengths are tested.
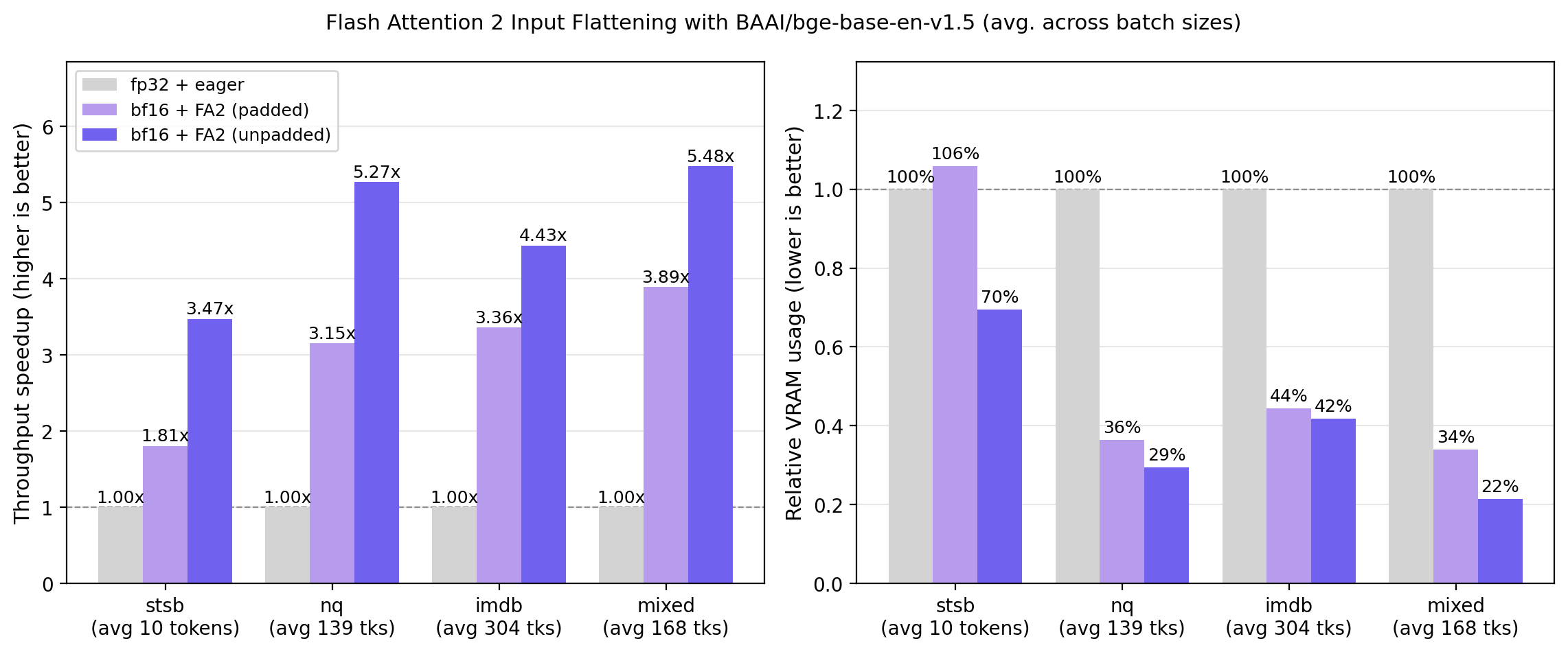
Flash Attention 2 with input flattening always outperforms standard Flash Attention 2, while using considerably less VRAM. The gains grow with the variance in input length, with the mixed dataset with wildly varying lengths (10-500 tokens) benefitting the most.
See also
The Transformers Attention Interface documentation
for a full overview of available attn_implementation options, including "flash_attention_2",
"flash_attention_3", "sdpa", and more.
Note
When running a Sentence Transformers model alongside a generative LLM on the same GPU, keep an eye on VRAM usage and generation latency, as the two can contend for memory and compute. For latency-sensitive local setups, moving small embedding models to the CPU can help (e.g. SentenceTransformer(..., device=\"cpu\") or model.encode(..., device=\"cpu\")).
ONNX
ONNX can be used to speed up inference by converting the model to ONNX format and using ONNX Runtime to run the model. To use the ONNX backend, you must install Sentence Transformers with the onnx or onnx-gpu extra for CPU or GPU acceleration, respectively:
pip install sentence-transformers[onnx-gpu]
# or
pip install sentence-transformers[onnx]
To convert a model to ONNX format, you can use the following code:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", backend="onnx")
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
If the model path or repository already contains a model in ONNX format, Sentence Transformers will automatically use it. Otherwise, it will convert the model to the ONNX format.
Note
If you wish to use the ONNX model outside of Sentence Transformers, you’ll need to perform pooling and/or normalization yourself. The ONNX export only converts the Transformer component, which outputs token embeddings, not sentence embeddings. To get sentence embeddings, you’ll need to apply the appropriate pooling strategy (like mean pooling) and any normalization that the original model uses.
All keyword arguments passed via model_kwargs will be passed on to ORTModel.from_pretrained. Some notable arguments include:
provider: ONNX Runtime provider to use for loading the model, e.g."CPUExecutionProvider". See https://onnxruntime.ai/docs/execution-providers/ for possible providers. If not specified, the strongest provider (E.g."CUDAExecutionProvider") will be used.file_name: The name of the ONNX file to load. If not specified, will default to"model.onnx"or otherwise"onnx/model.onnx". This argument is useful for specifying optimized or quantized models.export: A boolean flag specifying whether the model will be exported. If not provided,exportwill be set toTrueif the model repository or directory does not already contain an ONNX model.
Tip
It’s heavily recommended to save the exported model to prevent having to re-export it every time you run your code. You can do this by calling model.save_pretrained() if your model was local:
model = SentenceTransformer("path/to/my/model", backend="onnx")
model.save_pretrained("path/to/my/model")
or with model.push_to_hub() if your model was from the Hugging Face Hub:
model = SentenceTransformer("intfloat/multilingual-e5-small", backend="onnx")
model.push_to_hub("intfloat/multilingual-e5-small", create_pr=True)
Optimizing ONNX Models
ONNX models can be optimized using Optimum, allowing for speedups on CPUs and GPUs alike. To do this, you can use the export_optimized_onnx_model() function, which saves the optimized in a directory or model repository that you specify. It expects:
model: a Sentence Transformer, Sparse Encoder, or Cross Encoder model loaded with the ONNX backend.optimization_config:"O1","O2","O3", or"O4"representing optimization levels fromAutoOptimizationConfig, or anOptimizationConfiginstance.model_name_or_path: a path to save the optimized model file, or the repository name if you want to push it to the Hugging Face Hub.push_to_hub: (Optional) a boolean to push the optimized model to the Hugging Face Hub.create_pr: (Optional) a boolean to create a pull request when pushing to the Hugging Face Hub. Useful when you don’t have write access to the repository.file_suffix: (Optional) a string to append to the model name when saving it. If not specified, the optimization level name string will be used, or just"optimized"if the optimization config was not just a string optimization level.
See this example for exporting a model with optimization level 3 (basic and extended general optimizations, transformers-specific fusions, fast Gelu approximation):
Only optimize once:
from sentence_transformers import SentenceTransformer, export_optimized_onnx_model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", backend="onnx")
export_optimized_onnx_model(
model=model,
optimization_config="O3",
model_name_or_path="sentence-transformers/all-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
Before the pull request gets merged:
from sentence_transformers import SentenceTransformer
pull_request_nr = 2 # NOTE: Update this to the number of your pull request
model = SentenceTransformer(
"sentence-transformers/all-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
revision=f"refs/pr/{pull_request_nr}"
)
Once the pull request gets merged:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"sentence-transformers/all-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
)
Only optimize once:
from sentence_transformers import SentenceTransformer, export_optimized_onnx_model
model = SentenceTransformer("path/to/my/mpnet-legal-finetuned", backend="onnx")
export_optimized_onnx_model(
model=model, optimization_config="O3", model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
After optimizing:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"path/to/my/mpnet-legal-finetuned",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
)
Quantizing ONNX Models
ONNX models can be quantized to int8 precision using Optimum, allowing for faster inference on CPUs. To do this, you can use the export_dynamic_quantized_onnx_model() function, which saves the quantized in a directory or model repository that you specify. Dynamic quantization, unlike static quantization, does not require a calibration dataset. It expects:
model: a Sentence Transformer, Sparse Encoder, or Cross Encoder model loaded with the ONNX backend.quantization_config:"arm64","avx2","avx512", or"avx512_vnni"representing quantization configurations fromAutoQuantizationConfig, or anQuantizationConfiginstance.model_name_or_path: a path to save the quantized model file, or the repository name if you want to push it to the Hugging Face Hub.push_to_hub: (Optional) a boolean to push the quantized model to the Hugging Face Hub.create_pr: (Optional) a boolean to create a pull request when pushing to the Hugging Face Hub. Useful when you don’t have write access to the repository.file_suffix: (Optional) a string to append to the model name when saving it. If not specified,"qint8_quantized"will be used.
On my CPU, each of the default quantization configurations ("arm64", "avx2", "avx512", "avx512_vnni") resulted in roughly equivalent speedups.
See this example for quantizing a model to int8 with avx512_vnni:
Only quantize once:
from sentence_transformers import SentenceTransformer, export_dynamic_quantized_onnx_model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", backend="onnx")
export_dynamic_quantized_onnx_model(
model=model,
quantization_config="avx512_vnni",
model_name_or_path="sentence-transformers/all-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
Before the pull request gets merged:
from sentence_transformers import SentenceTransformer
pull_request_nr = 2 # NOTE: Update this to the number of your pull request
model = SentenceTransformer(
"sentence-transformers/all-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
revision=f"refs/pr/{pull_request_nr}",
)
Once the pull request gets merged:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"sentence-transformers/all-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
)
Only quantize once:
from sentence_transformers import SentenceTransformer, export_dynamic_quantized_onnx_model
model = SentenceTransformer("path/to/my/mpnet-legal-finetuned", backend="onnx")
export_dynamic_quantized_onnx_model(
model=model, quantization_config="avx512_vnni", model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
After quantizing:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"path/to/my/mpnet-legal-finetuned",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
)
OpenVINO
OpenVINO allows for accelerated inference on CPUs by exporting the model to the OpenVINO format. To use the OpenVINO backend, you must install Sentence Transformers with the openvino extra:
pip install sentence-transformers[openvino]
To convert a model to OpenVINO format, you can use the following code:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", backend="openvino")
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
If the model path or repository already contains a model in OpenVINO format, Sentence Transformers will automatically use it. Otherwise, it will convert the model to the OpenVINO format.
Note
If you wish to use the OpenVINO model outside of Sentence Transformers, you’ll need to perform pooling and/or normalization yourself. The OpenVINO export only converts the Transformer component, which outputs token embeddings, not sentence embeddings. To get sentence embeddings, you’ll need to apply the appropriate pooling strategy (like mean pooling) and any normalization that the original model uses.
model_kwargs will be passed on to OVBaseModel.from_pretrained(). Some notable arguments include:file_name: The name of the ONNX file to load. If not specified, will default to"openvino_model.xml"or otherwise"openvino/openvino_model.xml". This argument is useful for specifying optimized or quantized models.export: A boolean flag specifying whether the model will be exported. If not provided,exportwill be set toTrueif the model repository or directory does not already contain an OpenVINO model.
Tip
It’s heavily recommended to save the exported model to prevent having to re-export it every time you run your code. You can do this by calling model.save_pretrained() if your model was local:
model = SentenceTransformer("path/to/my/model", backend="openvino")
model.save_pretrained("path/to/my/model")
or with model.push_to_hub() if your model was from the Hugging Face Hub:
model = SentenceTransformer("intfloat/multilingual-e5-small", backend="openvino")
model.push_to_hub("intfloat/multilingual-e5-small", create_pr=True)
Quantizing OpenVINO Models
OpenVINO models can be quantized to int8 precision using Optimum Intel to speed up inference.
To do this, you can use the export_static_quantized_openvino_model() function,
which saves the quantized model in a directory or model repository that you specify.
Post-Training Static Quantization expects:
model: a Sentence Transformer, Sparse Encoder, or Cross Encoder model loaded with the OpenVINO backend.quantization_config: (Optional) The quantization configuration. This parameter accepts either:Nonefor the default 8-bit quantization, a dictionary representing quantization configurations, or anOVQuantizationConfiginstance.model_name_or_path: a path to save the quantized model file, or the repository name if you want to push it to the Hugging Face Hub.dataset_name: (Optional) The name of the dataset to load for calibration. If not specified, defaults tosst2subset from thegluedataset.dataset_config_name: (Optional) The specific configuration of the dataset to load.dataset_split: (Optional) The split of the dataset to load (e.g., ‘train’, ‘test’).column_name: (Optional) The column name in the dataset to use for calibration.push_to_hub: (Optional) a boolean to push the quantized model to the Hugging Face Hub.create_pr: (Optional) a boolean to create a pull request when pushing to the Hugging Face Hub. Useful when you don’t have write access to the repository.file_suffix: (Optional) a string to append to the model name when saving it. If not specified,"qint8_quantized"will be used.
See this example for quantizing a model to int8 with static quantization:
Only quantize once:
from sentence_transformers import SentenceTransformer, export_static_quantized_openvino_model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", backend="openvino")
export_static_quantized_openvino_model(
model=model,
quantization_config=None,
model_name_or_path="sentence-transformers/all-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
Before the pull request gets merged:
from sentence_transformers import SentenceTransformer
pull_request_nr = 2 # NOTE: Update this to the number of your pull request
model = SentenceTransformer(
"sentence-transformers/all-MiniLM-L6-v2",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
revision=f"refs/pr/{pull_request_nr}"
)
Once the pull request gets merged:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"sentence-transformers/all-MiniLM-L6-v2",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
Only quantize once:
from sentence_transformers import SentenceTransformer, export_static_quantized_openvino_model
from optimum.intel import OVQuantizationConfig
model = SentenceTransformer("path/to/my/mpnet-legal-finetuned", backend="openvino")
quantization_config = OVQuantizationConfig()
export_static_quantized_openvino_model(
model=model, quantization_config=quantization_config, model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
After quantizing:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"path/to/my/mpnet-legal-finetuned",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
Benchmarks
The following images show the benchmark results for the different backends on GPUs and CPUs. The results are averaged across 4 models of various sizes, 3 datasets, and numerous batch sizes.
Expand the benchmark details
Speedup ratio:
- Hardware: RTX 3090 GPU, i7-17300K CPU
-
Datasets: 2000 samples for GPU tests, 1000 samples for CPU tests.
- sentence-transformers/stsb: 38.9 characters on average (SD=13.9)
- sentence-transformers/natural-questions: answers only, 619.6 characters on average (SD=345.3)
- stanfordnlp/imdb: texts repeated 4 times, 9589.3 characters on average (SD=633.4)
-
Models:
- sentence-transformers/all-MiniLM-L6-v2: 22.7M parameters; batch sizes of 16, 32, 64, 128 and 256.
- BAAI/bge-base-en-v1.5: 109M parameters; batch sizes of 16, 32, 64, and 128.
- mixedbread-ai/mxbai-embed-large-v1: 335M parameters; batch sizes of 8, 16, 32, and 64. Also 128 and 256 for GPU tests.
- BAAI/bge-m3: 567M parameters; batch sizes of 2, 4. Also 8, 16, and 32 for GPU tests.
-
Evaluation:
- Semantic Textual Similarity: Spearman rank correlation based on cosine similarity on the sentence-transformers/stsb test set, computed via the EmbeddingSimilarityEvaluator.
- Information Retrieval: NDCG@10 based on cosine similarity on the entire NanoBEIR collection of datasets, computed via the InformationRetrievalEvaluator.
-
Backends:
-
torch-fp32: PyTorch with float32 precision (default). -
torch-fp16: PyTorch with float16 precision, viamodel_kwargs={"torch_dtype": "float16"}. -
torch-bf16: PyTorch with bfloat16 precision, viamodel_kwargs={"torch_dtype": "bfloat16"}. -
onnx: ONNX with float32 precision, viabackend="onnx". -
onnx-O1: ONNX with float32 precision and O1 optimization, viaexport_optimized_onnx_model(..., optimization_config="O1", ...)andbackend="onnx". -
onnx-O2: ONNX with float32 precision and O2 optimization, viaexport_optimized_onnx_model(..., optimization_config="O2", ...)andbackend="onnx". -
onnx-O3: ONNX with float32 precision and O3 optimization, viaexport_optimized_onnx_model(..., optimization_config="O3", ...)andbackend="onnx". -
onnx-O4: ONNX with float16 precision and O4 optimization, viaexport_optimized_onnx_model(..., optimization_config="O4", ...)andbackend="onnx". -
onnx-qint8: ONNX quantized to int8 with "avx512_vnni", viaexport_dynamic_quantized_onnx_model(..., quantization_config="avx512_vnni", ...)andbackend="onnx". The different quantization configurations resulted in roughly equivalent speedups. -
openvino: OpenVINO, viabackend="openvino". -
openvino-qint8: OpenVINO quantized to int8 viaexport_static_quantized_openvino_model(..., quantization_config=OVQuantizationConfig(), ...)andbackend="openvino".
-
For CPU, ONNX is also stronger for the stsb dataset with the shortest texts: 1.39x for ONNX, outperforming 1.29x for OpenVINO. ONNX with int8 quantization is even stronger with a 3.08x speedup. For longer texts, ONNX and OpenVINO can even perform slightly worse than PyTorch, so we recommend testing the different backends with your specific model and data to find the best one for your use case.
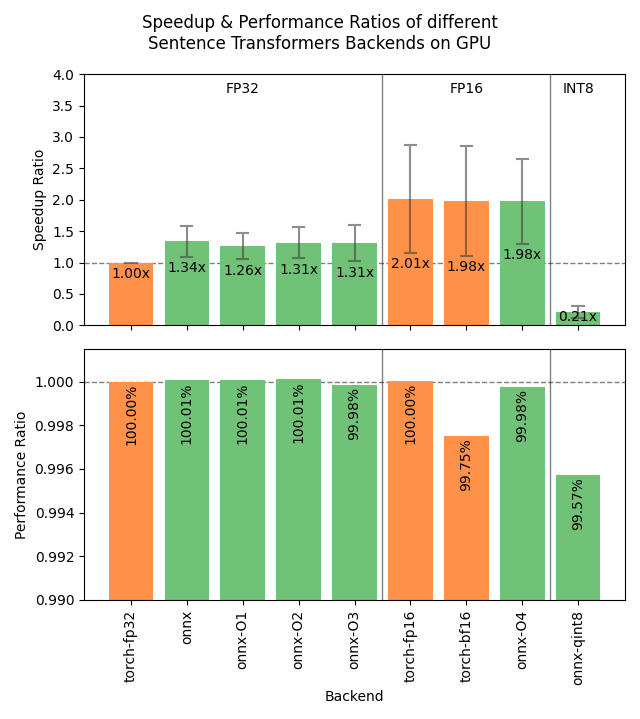
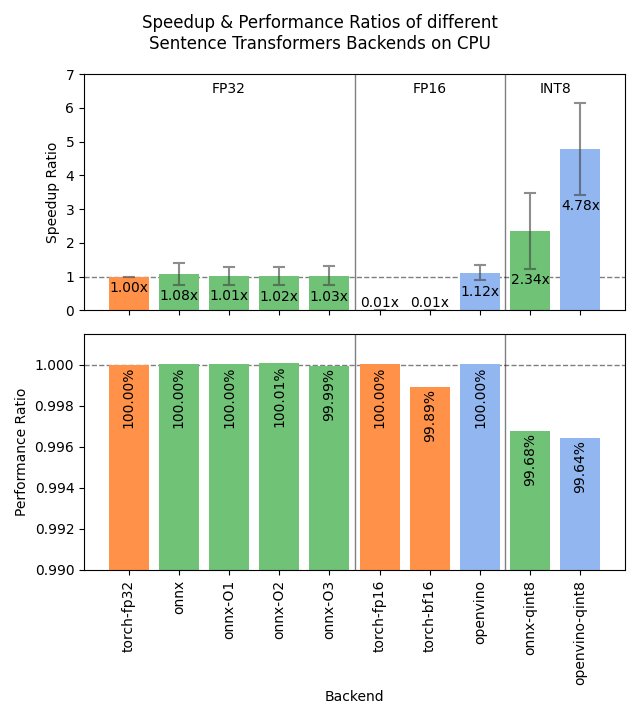
Recommendations
Based on the benchmarks, this flowchart should help you decide which backend to use for your model:
%%{init: {
"theme": "neutral",
"flowchart": {
"curve": "bumpY"
}
}}%%
graph TD
A(What is your hardware?) -->|GPU| B(Is your text usually smaller<br>than 500 characters?)
A -->|CPU| C(Is a 0.4% accuracy loss<br>acceptable?)
B -->|yes| D[onnx-O4]
B -->|no| F[float16]
C -->|yes| G[openvino-qint8]
C -->|no| H(Do you have an Intel CPU?)
H -->|yes| I[openvino]
H -->|no| J[onnx]
click D "#optimizing-onnx-models"
click F "#pytorch"
click G "#quantizing-openvino-models"
click I "#openvino"
click J "#onnx"
Note
Your mileage may vary, and you should always test the different backends with your specific model and data to find the best one for your use case.
User Interface
This Hugging Face Space provides a user interface for exporting, optimizing, and quantizing models for either ONNX or OpenVINO: