Training with Prompts
What are Prompts?
Many modern embedding models are trained with “instructions” or “prompts” following the INSTRUCTOR paper. These prompts are strings, prefixed to each text to be embedded, allowing the model to distinguish between different types of text.
For example, the mixedbread-ai/mxbai-embed-large-v1 model was trained with Represent this sentence for searching relevant passages: as the prompt for all queries. This prompt is stored in the model configuration under the prompt name "query", so users can specify that prompt_name in model.encode:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
query_embedding = model.encode("What are Pandas?", prompt_name="query")
# or
# query_embedding = model.encode("What are Pandas?", prompt="Represent this sentence for searching relevant passages: ")
document_embeddings = model.encode([
"Pandas is a software library written for the Python programming language for data manipulation and analysis.",
"Pandas are a species of bear native to South Central China. They are also known as the giant panda or simply panda.",
"Koala bears are not actually bears, they are marsupials native to Australia.",
])
similarity = model.similarity(query_embedding, document_embeddings)
print(similarity)
# => tensor([[0.7594, 0.7560, 0.4674]])
See Prompt Templates for more information about inference with prompts.
Why would we train with Prompts?
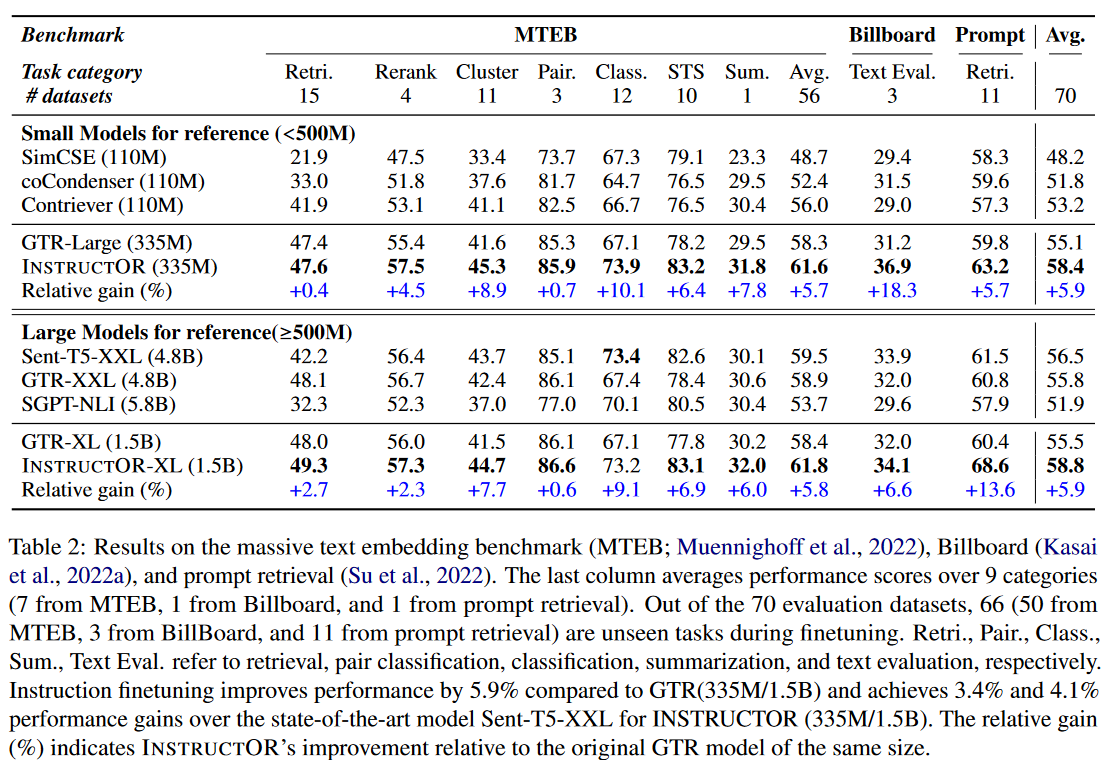
The INSTRUCTOR paper showed that adding prompts or instructions before each text could improve model performance by an average of ~6%, with major gains especially for classification, clustering, and semantic textual similarity. Note that the performance improvements for retrieval are notably lower at 0.4% and 2.7% for small and large models, respectively.
More recently, the BGE paper showed similar findings, showing about a 1.4% performance increase for retrieval if the query is prefixed with Represent this sentence for searching relevant passages: . The authors conclude that using instructions may substantially contribute to the quality of task-specific fine-tuning.
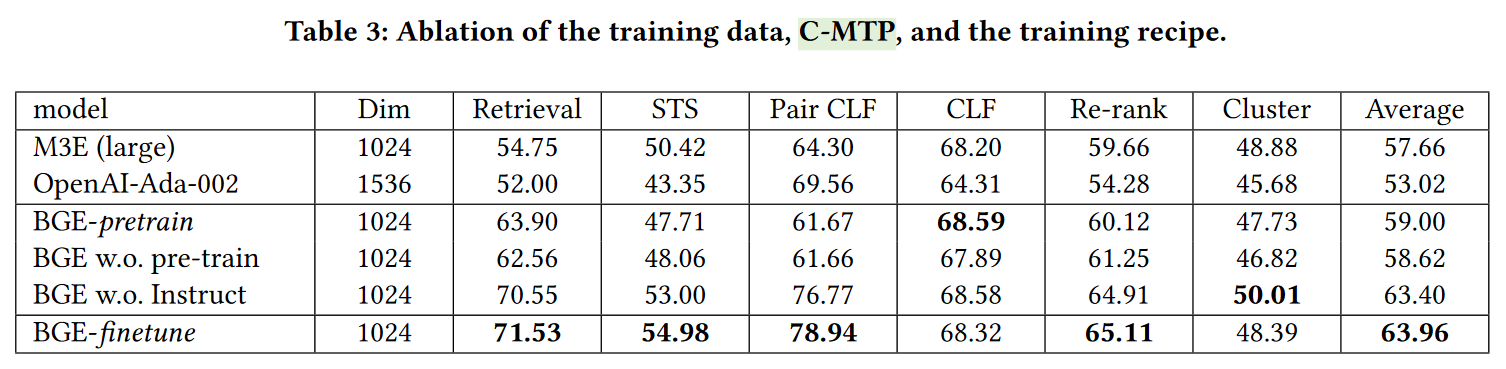
In essence, using instructions or prompts allows for improved performance as long as they are used both during training and inference.
How do we train with Prompts?
Since the v3.3.0 Sentence Transformers release, it’s possible to finetune embedding models with prompts using the prompts argument in the SentenceTransformerTrainingArguments class. There are 4 separate accepted formats for this argument:
str: A single prompt to use for all columns in all datasets. For example:args = SentenceTransformerTrainingArguments( ..., prompts="text: ", ..., )
Dict[str, str]: A dictionary mapping column names to prompts, applied to all datasets. For example:args = SentenceTransformerTrainingArguments( ..., prompts={ "query": "query: ", "answer": "document: ", }, ..., )
Dict[str, str]: A dictionary mapping dataset names to prompts. This should only be used if your training/evaluation/test datasets are aDatasetDictor a dictionary ofDataset. For example:args = SentenceTransformerTrainingArguments( ..., prompts={ "stsb": "Represent this text for semantic similarity search: ", "nq": "Represent this text for retrieval: ", }, ..., )
Dict[str, Dict[str, str]]: A dictionary mapping dataset names to dictionaries mapping column names to prompts. This should only be used if your training/evaluation/test datasets are aDatasetDictor a dictionary ofDataset. For example:args = SentenceTransformerTrainingArguments( ..., prompts={ "stsb": { "sentence1": "sts: ", "sentence2": "sts: ", }, "nq": { "query": "query: ", "document": "document: ", }, }, ..., )
Additionally, some research papers (INSTRUCTOR, NV-Embed) exclude the prompt from the mean pooling step, such that it’s only used in the Transformer blocks. In Sentence Transformers, this can be configured with the include_prompt argument/attribute in the Pooling module or via the SentenceTransformer.set_pooling_include_prompt() method. In my personal experience, models that include the prompt in the pooling tend to perform better.
Training Script
See the following script as an example of how to train with prompts in practice:
training_nq_prompts.py: This script finetunes mpnet-base on 100k query-answer pairs from the natural-questions dataset using the
CachedMultipleNegativesRankingLossloss. The model is evaluated during training using theNanoBEIREvaluator.
This script has two variables that affect 1) whether prompts are used and 2) whether prompts are included in the pooling. I have finetuned both mpnet-base and bert-base-uncased under the various different settings, resulting in a 0.66% and 0.90% relative improvements on NDCG@10 at no extra cost.
Running the script under various settings resulted in these checkpoints:
Note
mpnet-base seems to be a tad unstable when training with prompts and excluding those prompts in the pooling: the loss spikes at some point, an effect not observed with e.g. bert-base-uncased.
For these two models, the model trained with prompts consistently outperforms the baseline model all throughout training:
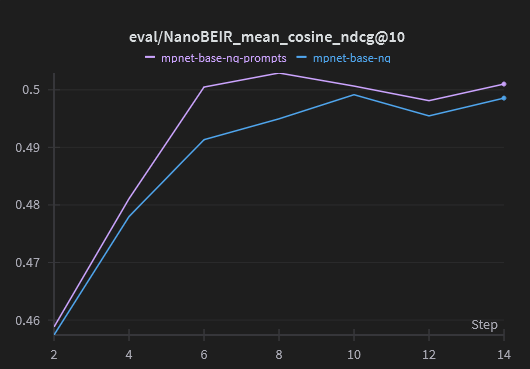
Additionally, the model trained with prompts includes these prompts in the training dataset details in the automatically generated model card: tomaarsen/mpnet-base-nq-prompts#natural-questions.
Important
If you train with prompts, then it’s heavily recommended to store prompts in the model configuration as a mapping of prompt names to prompt strings. You can do this by initializing the SentenceTransformer with a prompts dictionary before saving it, updating the model.prompts of a loaded model before saving it, and/or updating the config_sentence_transformers.json file of the saved model.
After adding the prompts in the model configuration, the final usage of the prompt-trained model becomes:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("tomaarsen/mpnet-base-nq-prompts")
query_embedding = model.encode("What are Pandas?", prompt_name="query")
document_embeddings = model.encode([
"Pandas is a software library written for the Python programming language for data manipulation and analysis.",
"Pandas are a species of bear native to South Central China. They are also known as the giant panda or simply panda.",
"Koala bears are not actually bears, they are marsupials native to Australia.",
],
prompt_name="document",
)
similarity = model.similarity(query_embedding, document_embeddings)
print(similarity)
# => tensor([[0.4725, 0.7339, 0.4369]])
Running the script under various settings resulted in these checkpoints:
For these three models, the model trained with prompts consistently outperforms the baseline model all throughout training, except for the very first evaluation. The model that excludes the prompt in the mean pooling consistently performs notably worse than either of the other two.
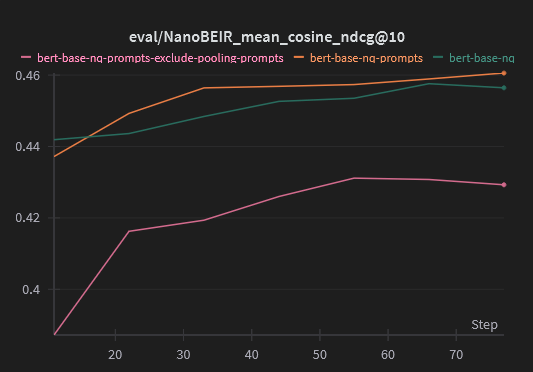
Additionally, the model trained with prompts includes these prompts in the training dataset details in the automatically generated model card: tomaarsen/bert-base-nq-prompts#natural-questions.
Important
If you train with prompts, then it’s heavily recommended to store prompts in the model configuration as a mapping of prompt names to prompt strings. You can do this by initializing the SentenceTransformer with a prompts dictionary before saving it, updating the model.prompts of a loaded model before saving it, and/or updating the config_sentence_transformers.json file of the saved model.
After adding the prompts in the model configuration, the final usage of the prompt-trained model becomes:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("tomaarsen/bert-base-nq-prompts")
query_embedding = model.encode("What are Pandas?", prompt_name="query")
document_embeddings = model.encode([
"Pandas is a software library written for the Python programming language for data manipulation and analysis.",
"Pandas are a species of bear native to South Central China. They are also known as the giant panda or simply panda.",
"Koala bears are not actually bears, they are marsupials native to Australia.",
],
prompt_name="document",
)
similarity = model.similarity(query_embedding, document_embeddings)
print(similarity)
# => tensor([[0.3955, 0.8226, 0.5706]])