Natural Language Inference
Given two sentence (premise and hypothesis), Natural Language Inference (NLI) is the task of deciding if the premise entails the hypothesis, if they are contradiction, or if they are neutral. Commonly used NLI dataset are SNLI and MultiNLI.
Conneau et al. showed that NLI data can be quite useful when training Sentence Embedding methods. We also found this in our Sentence-BERT-Paper and often use NLI as a first fine-tuning step for sparse encoder methods.
To train on NLI, see the following example file:
-
This script trains a SparseEncoder (specifically a SPLADE-like model, fine-tuning e.g., naver/splade-cocondenser-ensembledistil) for NLI. It uses the
SpladeLoss. This loss is designed for training SPLADE-style models and combines two main components: 1. A ranking loss, typicallySparseMultipleNegativesRankingLoss, to ensure that relevant (e.g., entailment) pairs have higher similarity scores than irrelevant ones (in-batch negatives). 2. Regularization terms (controlled by document_regularizer_weight and potentially other parameters in the loss) to encourage sparsity in the learned term weightings in the sparse vectors. This is a key characteristic of SPLADE models, leading to highly efficient and effective sparse representations.The script uses the AllNLI dataset, likely with the “pair-score” or “pair” configuration to extract (anchor, positive) pairs (e.g., premise and entailment hypothesis) for the ranking component of the loss.
Data
We combine SNLI and MultiNLI into a dataset we call AllNLI. These two datasets contain sentence pairs and one of three labels: entailment, neutral, contradiction:
| Sentence A (Premise) | Sentence B (Hypothesis) | Label |
|---|---|---|
| A soccer game with multiple males playing. | Some men are playing a sport. | entailment |
| An older and younger man smiling. | Two men are smiling and laughing at the cats playing on the floor. | neutral |
| A man inspects the uniform of a figure in some East Asian country. | The man is sleeping. | contradiction |
We format AllNLI in a few different subsets, compatible with different loss functions. For the train_splade_nli.py script, the data is typically processed into (anchor, positive) pairs for the ranking loss component. For example, entailment pairs from NLI can serve as (anchor, positive) pairs.
The pair subset of AllNLI provides (anchor, positive) pairs directly.
The triplet subset of AllNLI provides (anchor, positive, negative) triplets, where the negative is a hard negative (contradiction). While SpladeLoss primarily uses positive pairs for its ranking component, hard negatives could potentially be incorporated depending on the exact SparseMultipleNegativesRankingLoss configuration.
SpladeLoss
The SpladeLoss is used in train_splade_nli.py. It’s specifically designed for training SPLADE (Sparse Lexical and Expansion) models. It wraps a ranking loss, such as SparseMultipleNegativesRankingLoss, and adds regularization terms to promote sparsity in the output vectors.
Ranking Component: SparseMultipleNegativesRankingLoss
The underlying ranking loss operates on sentence pairs [(a1, b1), …, (an, bn)] where (ai, bi) are similar sentences (e.g., premise and its entailed hypothesis) and (ai, bj) for i != j are treated as dissimilar sentences (in-batch negatives). The loss minimizes the distance (or maximizes similarity) between (ai, bi) while simultaneously maximizing the distance (or minimizing similarity) between (ai, bj) for all i != j.
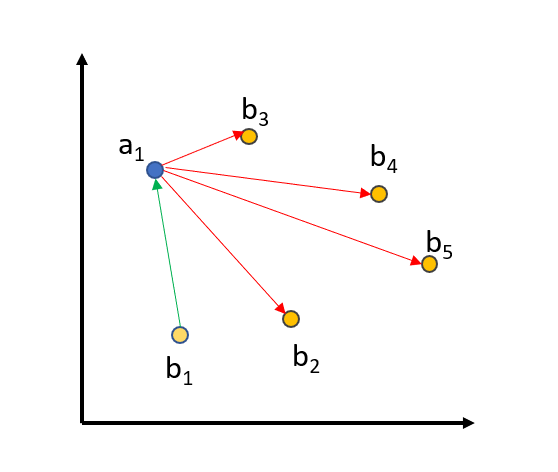
Using this with NLI data means defining entailment pairs as positive pairs. For example, (“A soccer game with multiple males playing.”, “Some men are playing a sport.”) should be close in the sparse vector space.
Sparsity Regularization
A key part of SpladeLoss is the regularization (e.g., FLOPS regularization via document_regularizer_weight) applied to the term weights in the sparse output vectors. This encourages the model to select only the most important terms for representation, leading to very sparse vectors, which is beneficial for efficient retrieval.