MS MARCO
MS MARCO Passage Ranking is a large dataset to train models for information retrieval. It consists of about 500k real search queries from Bing search engine with the relevant text passage that answers the query. This page shows how to train Cross Encoder models on this dataset so that it can be used for searching text passages given queries (key words, phrases or questions).
If you are interested in how to use these models, see Application - Retrieve & Re-Rank. There are pre-trained models available, which you can directly use without the need of training your own models. For more information, see Pretrained Cross-Encoders for MS MARCO.
Cross Encoder
A Cross Encoder accepts both a query and a possible relevant passage and returns a score denoting how relevant the passage is for the given query. Often times, a torch.nn.Sigmoid is applied over the raw output prediction, casting it to a value between 0 and 1.
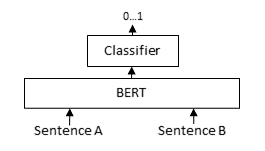
CrossEncoder models are often used for re-ranking: Given a list with possible relevant passages for a query, for example retrieved from a SentenceTransformer model / BM25 / Elasticsearch, the cross-encoder re-ranks this list so that the most relevant passages are the top of the result list.
Training Scripts
We provide several training scripts with various loss functions to train a CrossEncoder on MS MARCO.
In all scripts, the model is evaluated on subsets of MS MARCO, NFCorpus, NQ via the CrossEncoderNanoBEIREvaluator.
training_ms_marco_bce_preprocessed.py:
This example uses
BinaryCrossEntropyLosson a pre-processed MS MARCO dataset.-
This example also uses the
BinaryCrossEntropyLoss, but now the dataset pre-processing into(query, answer)withlabelas 1 or 0 is done in the training script. -
This example uses the
CachedMultipleNegativesRankingLoss. The script applies dataset pre-processing into(query, answer, negative_1, negative_2, negative_3, negative_4, negative_5). -
This example uses the
ListNetLoss. The script applies dataset pre-processing into(query, [doc1, doc2, ..., docN])withlabelsas[score1, score2, ..., scoreN]. -
This example uses the
LambdaLosswith theNDCGLoss2PPSchemeloss scheme. The script applies dataset pre-processing into(query, [doc1, doc2, ..., docN])withlabelsas[score1, score2, ..., scoreN]. training_ms_marco_lambda_preprocessed.py:
This example uses the
LambdaLosswith theNDCGLoss2PPSchemeloss scheme on a pre-processed MS MARCO dataset.training_ms_marco_lambda_hard_neg.py:
This example extends the above example by increasing the size of the training dataset by mining hard negatives with
mine_hard_negatives().-
This example uses the
ListMLELoss. The script applies dataset pre-processing into(query, [doc1, doc2, ..., docN])withlabelsas[score1, score2, ..., scoreN]. training_ms_marco_plistmle.py:
This example uses the
PListMLELosswith the defaultPListMLELambdaWeightposition weighting. The script applies dataset pre-processing into(query, [doc1, doc2, ..., docN])withlabelsas[score1, score2, ..., scoreN].-
This example uses the
RankNetLoss. The script applies dataset pre-processing into(query, [doc1, doc2, ..., docN])withlabelsas[score1, score2, ..., scoreN]. -
This example uses the
ADRMSELosson the RankZephyr-ordered MS MARCO subset, the LLM-distillation setting the loss was designed for. Per-document scores are derived from the LLM-provided order (top doc gets the highest score).
Out of these training scripts, I suspect that training_ms_marco_lambda_preprocessed.py, training_ms_marco_lambda_hard_neg.py or training_ms_marco_bce_preprocessed.py produces the strongest model, as anecdotally LambdaLoss and BinaryCrossEntropyLoss are quite strong. It seems that LambdaLoss > PListMLELoss > ListNetLoss > RankNetLoss > ListMLELoss out of all learning to rank losses, but your mileage may vary. The Rank-DistiLLM paper reports ADRMSELoss within ~0.002 nDCG@10 of RankNetLoss on LLM-distilled data.
Additionally, you can also train with Distillation. See Cross Encoder > Training Examples > Distillation for more details.
Inference
You can perform inference using any of the pre-trained CrossEncoder models for MS MARCO like so:
from sentence_transformers import CrossEncoder
# 1. Load a pre-trained CrossEncoder model
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2")
# 2. Predict scores for a pair of sentences
scores = model.predict([
("How many people live in Berlin?", "Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers."),
("How many people live in Berlin?", "Berlin is well known for its museums."),
])
# => array([ 8.607138 , -4.3200774], dtype=float32)
# 3. Rank a list of passages for a query
query = "How many people live in Berlin?"
passages = [
"Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.",
"Berlin is well known for its museums.",
"In 2014, the city state Berlin had 37,368 live births (+6.6%), a record number since 1991.",
"The urban area of Berlin comprised about 4.1 million people in 2014, making it the seventh most populous urban area in the European Union.",
"The city of Paris had a population of 2,165,423 people within its administrative city limits as of January 1, 2019",
"An estimated 300,000-420,000 Muslims reside in Berlin, making up about 8-11 percent of the population.",
"Berlin is subdivided into 12 boroughs or districts (Bezirke).",
"In 2015, the total labour force in Berlin was 1.85 million.",
"In 2013 around 600,000 Berliners were registered in one of the more than 2,300 sport and fitness clubs.",
"Berlin has a yearly total of about 135 million day visitors, which puts it in third place among the most-visited city destinations in the European Union.",
]
ranks = model.rank(query, passages)
# Print the scores
print("Query:", query)
for rank in ranks:
print(f"{rank['score']:.2f}\t{passages[rank['corpus_id']]}")
"""
Query: How many people live in Berlin?
8.92 The urban area of Berlin comprised about 4.1 million people in 2014, making it the seventh most populous urban area in the European Union.
8.61 Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.
8.24 An estimated 300,000-420,000 Muslims reside in Berlin, making up about 8-11 percent of the population.
7.60 In 2014, the city state Berlin had 37,368 live births (+6.6%), a record number since 1991.
6.35 In 2013 around 600,000 Berliners were registered in one of the more than 2,300 sport and fitness clubs.
5.42 Berlin has a yearly total of about 135 million day visitors, which puts it in third place among the most-visited city destinations in the European Union.
3.45 In 2015, the total labour force in Berlin was 1.85 million.
0.33 Berlin is subdivided into 12 boroughs or districts (Bezirke).
-4.24 The city of Paris had a population of 2,165,423 people within its administrative city limits as of January 1, 2019
-4.32 Berlin is well known for its museums.
"""