Model Distillation
This page contains an example to make SentenceTransformer models faster, cheaper and lighter. These light models achieve 97.5% - 100% performance of the original model on downstream tasks.
Knowledge Distillation
Knowledge distillation describes the process to transfer knowledge from a teacher model to a student model. It can be used to extend sentence embeddings to new languages (Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation), but the traditional approach is to have a slow (but well performing) teacher model and a fast student model.
The fast student model imitates the teacher model and achieves by this a high performance.
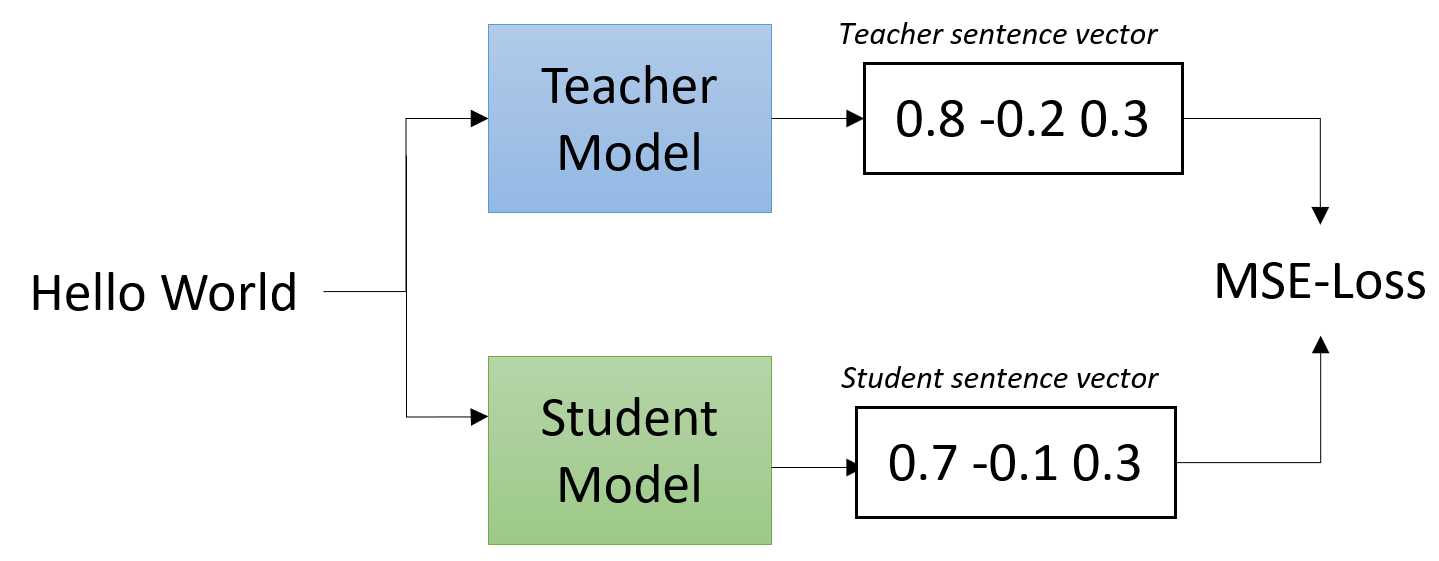
We implement two options for creating the student model:
model_distillation.py: Use a light transformer model like TinyBERT or BERT-Small to imitate the bigger teacher. Trained with
EmbedDistillLoss, which carries an optional learnable projection so the student and teacher don’t have to share an embedding dimension. The student keeps its native (smaller) output dimension after training.model_distillation_layer_reduction.py: Take the teacher model and keep only certain layers, for example, only 4 layers. Trained with
MSELoss; no projection is needed because the layer-reduced student inherits the teacher’s hidden size, so it stays a drop-in replacement at the same dimensionality.
Option 2) works usually better, as we keep most of the weights from the teacher. In Option 1, we have to tune all weights in the student from scratch.
Speed - Performance Trade-Off
Smaller models are faster, but show a (slightly) worse performance when evaluated on down stream tasks. To get an impression of this trade-off, we show some numbers of the stsb-roberta-base model with different number of layers:
| Layers | STSbenchmark Performance | Performance Decrease | Speed (Sent. / Sec. on V100-GPU) |
|---|---|---|---|
| teacher: 12 | 85.44 | - | 2300 |
| 8 | 85.54 | +0.1% | 3200 (~1.4x) |
| 6 | 85.23 | -0.2% | 4000 (~1.7x) |
| 4 | 84.92 | -0.6% | 5300 (~2.3x) |
| 3 | 84.39 | -1.2% | 6500 (~2.8x) |
| 2 | 83.32 | -2.5% | 7700 (~3.3x) |
| 1 | 80.86 | -5.4% | 9200 (~4.0x) |
Dimensionality Reduction
Warning
Since writing this, Embedding Quantization has been introduced as the go-to approach for shrinking embedding sizes. Following Thakur et al., We recommend that approach over PCA.
By default, the pretrained models output embeddings with size 768 (base-models) or with size 1024 (large-models). However, when you store millions of embeddings, this can require quite a lot of memory / storage.
dimensionality_reduction.py contains a simple example how to reduce the embedding dimension to any size by using Principle Component Analysis (PCA). In that example, we reduce 768 dimension to 128 dimension, reducing the storage requirement by factor 6. The performance only slightly drops from 85.44 to 84.96 on the STS benchmark dataset.
This dimensionality reduction technique can easily be applied to existent models. We could even reduce the embeddings size to 32, reducing the storage requirement by factor 24 (performance decreases to 81.82).
Note: This technique neither improves the runtime, nor the memory requirement for running the model. It only reduces the needed space to store embeddings, for example, for semantic search.
Quantization
A quantized model executes some or all of the operations with integers rather than floating point values. This allows for a more compact models and the use of high performance vectorized operations on many hardware platforms.
For models that are run on CPUs, this can yield 40% smaller models and a faster inference time: Depending on the CPU, speedup are between 15% and 400%. Model quantization is (as of now) not supported for GPUs by PyTorch.
For an example, see model_quantization.py
Note
The quantization support of Sentence Transformers is still being improved.