Natural Language Inference
Given two sentence (premise and hypothesis), Natural Language Inference (NLI) is the task of deciding if the premise entails the hypothesis, if they are contradiction, or if they are neutral. Commonly used NLI dataset are SNLI and MultiNLI.
Conneau et al. showed that NLI data can be quite useful when training Sentence Embedding methods. We also found this in our Sentence-BERT-Paper and often use NLI as a first fine-tuning step for sentence embedding methods.
To train on NLI, see the following example files:
-
This example uses
SoftmaxLossas described in the original [Sentence Transformers paper](https://huggingface.co/papers/1908.10084). -
The
SoftmaxLossas used in our original SBERT paper does not yield optimal performance. A better loss isMultipleNegativesRankingLoss, where we provide pairs or triplets. In this script, we provide a triplet of the format: (anchor, entailment_sentence, contradiction_sentence). The NLI data provides such triplets. TheMultipleNegativesRankingLossyields much higher performances and is more intuitive thanSoftmaxLoss. We have used this loss to train the paraphrase model in our Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation paper. -
Following the GISTEmbed paper, we can modify the in-batch negative selection from
MultipleNegativesRankingLossusing a guiding model. Candidate negative pairs are ignored during training if the guiding model considers the pair to be too similar. In practice, theGISTEmbedLosstends to produce a stronger training signal thanMultipleNegativesRankingLossat the cost of some training overhead for running inference on the guiding model. -
This example uses
AnglELosson the triplet subset of AllNLI. Each example consists of (premise, entailment, contradiction), where the entailment sentence is treated as a positive and the contradiction sentence as a hard negative. Internally,AnglELossconverts these triplets (and more generally, n-tuples of the form (anchor, positive, negative_1, …, negative_n)) into pairwise comparisons so that the anchor–positive pairs are ranked above the anchor–negative pairs.
You can also train and use CrossEncoder models for this task. See Cross Encoder > Training Examples > Natural Language Inference for more details.
Data
We combine SNLI and MultiNLI into a dataset we call AllNLI. These two datasets contain sentence pairs and one of three labels: entailment, neutral, contradiction:
| Sentence A (Premise) | Sentence B (Hypothesis) | Label |
|---|---|---|
| A soccer game with multiple males playing. | Some men are playing a sport. | entailment |
| An older and younger man smiling. | Two men are smiling and laughing at the cats playing on the floor. | neutral |
| A man inspects the uniform of a figure in some East Asian country. | The man is sleeping. | contradiction |
We format AllNLI in a few different subsets, compatible with different loss functions. See for example the triplet subset of AllNLI.
SoftmaxLoss
Conneau et al. described how a softmax classifier on top of a siamese network can be used to learn meaningful sentence representation. We can achieve this by using SoftmaxLoss:
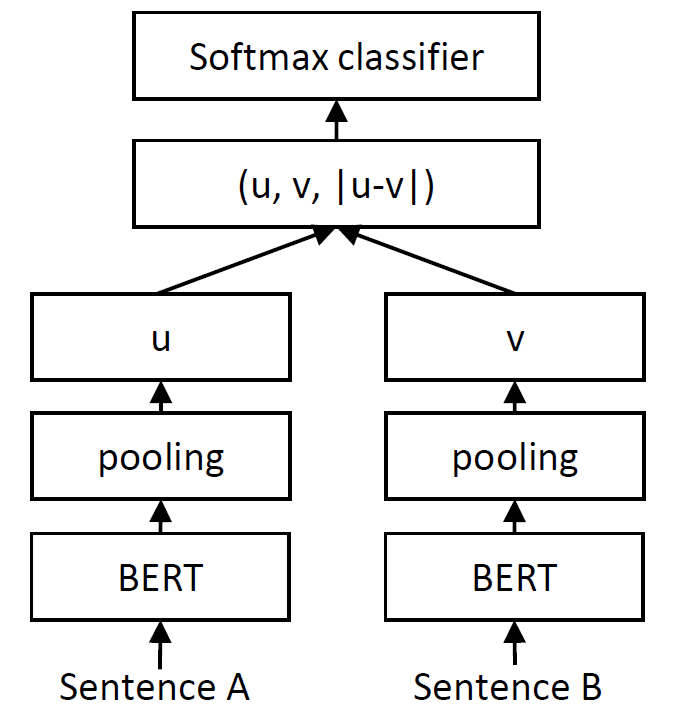
We pass the two sentences through our SentenceTransformer model and get the sentence embeddings u and v. We then concatenate u, v and |u-v| to form one long vector. This vector is then passed to a softmax classifier, which predicts our three classes (entailment, neutral, contradiction).
This setup learns sentence embeddings that can later be used for wide variety of tasks.
MultipleNegativesRankingLoss
That the SoftmaxLoss with NLI data produces (relatively) good sentence embeddings is rather coincidental. The MultipleNegativesRankingLoss is much more intuitive and produces significantly better sentence representations.
The training data for MultipleNegativesRankingLoss consists of sentence pairs [(a1, b1), …, (an, bn)] where we assume that (ai, bi) are similar sentences and (ai, bj) are dissimilar sentences for i != j. The minimizes the distance between (ai, bi) while it simultaneously maximizes the distance (ai, bj) for all i != j. For example, in the following picture:
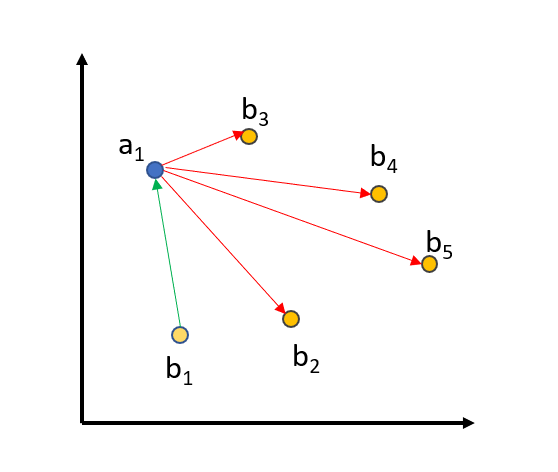
The distance between (a1, b1) is reduced, while the distance between (a1, b2…5) will be increased. The same is done for a2, …, a5.
Using MultipleNegativesRankingLoss with NLI is rather easy: We define sentences that have an entailment label as positive pairs. E.g, we have pairs like (“A soccer game with multiple males playing.”, “Some men are playing a sport.”) and want that these pairs are close in vector space. The pair subset of AllNLI has been prepared in this format.
MultipleNegativesRankingLoss with Hard Negatives
We can further improve MultipleNegativesRankingLoss by providing triplets rather than pairs: [(a1, b1, c1), …, (an, bn, cn)]. The samples for ci are so-called hard-negatives: On a lexical level, they are similar to ai and bi, but on a semantic level, they mean different things and should not be close to ai in the vector space.
For NLI data, we can use the contradiction-label to create such triplets with a hard negative. So our triplets look like this: (”A soccer game with multiple males playing.”, “Some men are playing a sport.”, “A group of men playing a baseball game.”). We want the sentences “A soccer game with multiple males playing.” and “Some men are playing a sport.” to be close in the vector space, while there should be a larger distance between “A soccer game with multiple males playing.” and “A group of men playing a baseball game.”. The triplet subset of AllNLI has been prepared in this format.
GISTEmbedLoss
MultipleNegativesRankingLoss can be extended even further by recognizing that the in-batch negative sampling as shown in this example is a bit flawed. In particular, we automatically assume that the pairs (a1, b2), …, (a1, bn) are negative, but that does not strictly have to be true.
To address this, GISTEmbedLoss uses a Sentence Transformer model to guide the in-batch negative sample selection. In particular, if the guide model considers the similarity of (a1, bn) to be larger than (a1, b1), then the (a1, bn) pair is considered a false negative and consequently ignored in the training process. In essence, this results in higher quality training data for the model.