Unsupervised Learning
This page contains a collection of unsupervised learning methods to learn sentence embeddings. The methods have in common that they do not require labeled training data. Instead, they can learn semantically meaningful sentence embeddings just from the text itself.
Note
Unsupervised learning approaches are still an activate research area and in many cases the models perform rather poorly compared to models that are using training pairs as provided in our training data collection. A better approach is Domain Adaptation where you combine unsupervised learning on your target domain with existent labeled data. This should give the best performance on your specific corpus.
TSDAE
In our work TSDAE (Transformer-based Denoising AutoEncoder) we present an unsupervised sentence embedding learning method based on denoising auto-encoders:
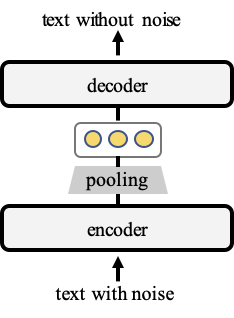
We add noise to the input text, in our case, we delete about 60% of the words in the text. The encoder maps this input to a fixed-sized sentence embeddings. A decoder then tries to re-create the original text without the noise. Later, we use the encoder as the sentence embedding methods.
See TSDAE for more information and training examples.
SimCSE
Gao et al. present in SimCSE: Simple Contrastive Learning of Sentence Embeddings a method that passes the same sentence twice to the sentence embedding encoder. Due to the drop-out, it will be encoded at slightly different positions in vector space.
The distance between these two embeddings will be minimized, while the distance to other embeddings of the other sentences in the same batch will be maximized.
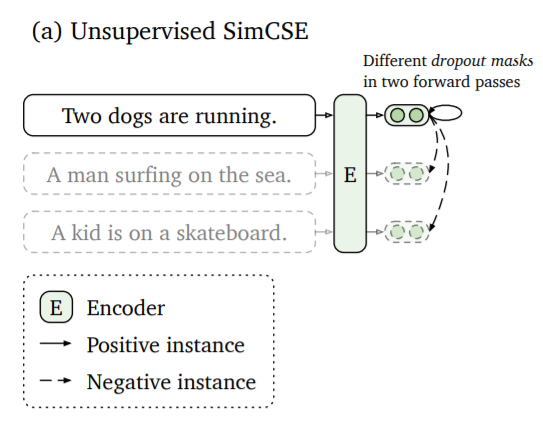
See SimCSE for more information and training examples.
CT
Carlsson et al. present in Semantic Re-Tuning With Contrastive Tension (CT) an unsupervised method that uses two models: If the same sentences are passed to Model1 and Model2, then the respective sentence embeddings should get a large dot-score. If the different sentences are passed, then the sentence embeddings should get a low score.
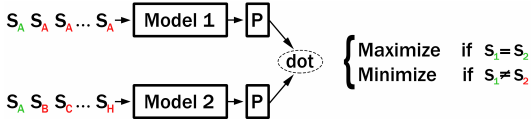
See CT for more information and training examples.
CT (In-Batch Negative Sampling)
The CT method from Carlsson et al. provides sentence pairs to the two models. This can be improved by using in-batch negative sampling: Model1 and Model2 both encode the same set of sentences. We maximize the scores for matching indexes (i.e. Model1(S_i) and Model2(S_i)) while we minimize the scores for different indexes (i.e. Model1(S_i) and Model2(S_j) for i != j).
See CT_In-Batch_Negatives for more information and training examples.
Masked Language Model (MLM)
BERT showed that Masked Language Model (MLM) is a powerful pre-training approach. It is advisable to first run MLM a large dataset from your domain before you do fine-tuning. See MLM for more information and training examples.
GenQ
In our paper BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models we present a method to learn a semantic search method by generating queries for given passages. This method has been improved in GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval.
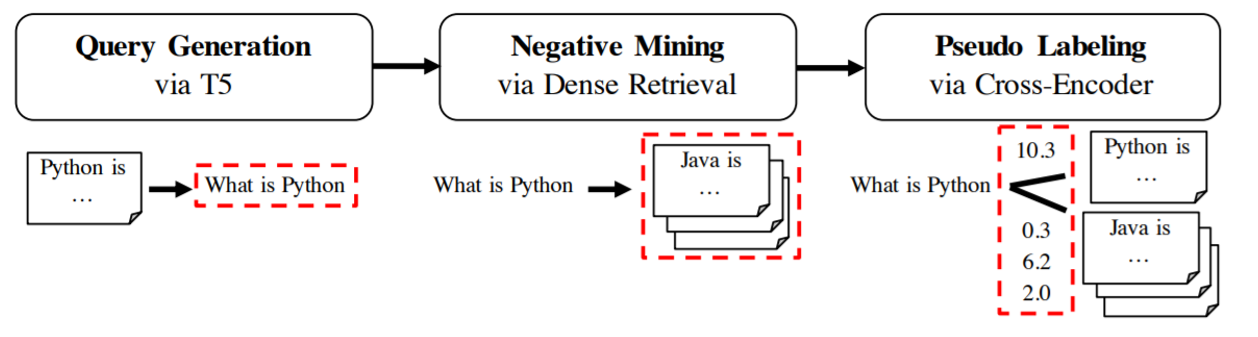
We pass all passages in our collection through a trained T5 model, which generates potential queries from users. We then use these (query, passage) pairs to train a SentenceTransformer model.
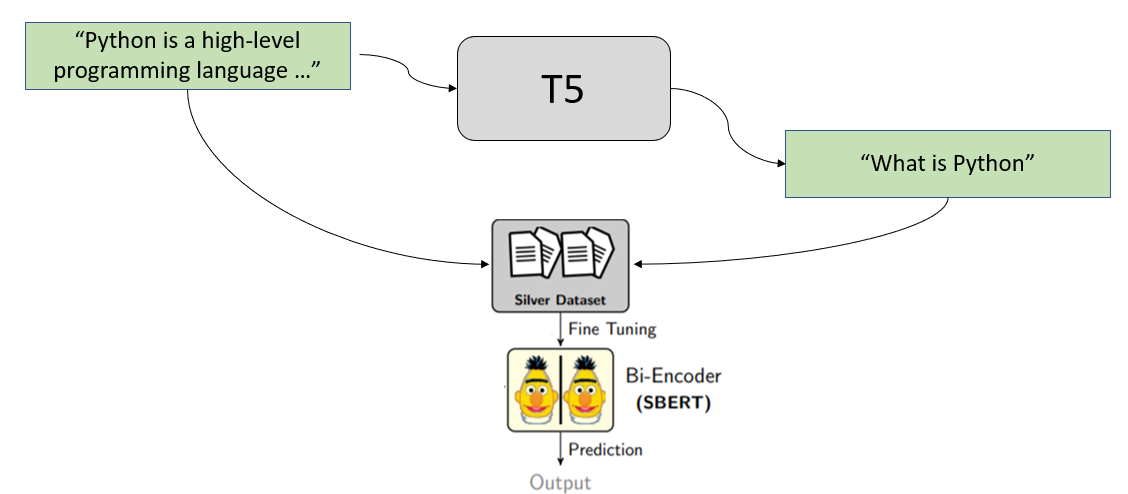
See GenQ for more information and training examples. See GPL for the improved version that uses a multi-step training approach.
GPL
In GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval we show an improved version of GenQ, which combines the generation with negative mining and pseudo labeling using a Cross-Encoder. It leads to significantly improved results. See Domain Adaptation for more information.
Performance Comparison
In our paper TSDAE we compare approaches for sentence embedding tasks, and in GPL we compare them for semantic search tasks (given a query, find relevant passages). While the unsupervised approach achieve acceptable performances for sentence embedding tasks, they perform poorly for semantic search tasks.