Clustering
Sentence-Transformers can be used in different ways to perform clustering of small or large set of sentences.
k-Means
kmeans.py contains an example of using K-means Clustering Algorithm. K-Means requires that the number of clusters is specified beforehand. The sentences are clustered in groups of about equal size.
Agglomerative Clustering
agglomerative.py shows an example of using Hierarchical clustering using the Agglomerative Clustering Algorithm. In contrast to k-means, we can specify a threshold for the clustering: Clusters below that threshold are merged. This algorithm can be useful if the number of clusters is unknown. By the threshold, we can control if we want to have many small and fine-grained clusters or few coarse-grained clusters.
Fast Clustering
Agglomerative Clustering for larger datasets is quite slow, so it is only applicable for maybe a few thousand sentences.
In fast_clustering.py we present a clustering algorithm that is tuned for large datasets (50k sentences in less than 5 seconds). In a large list of sentences it searches for local communities: A local community is a set of highly similar sentences.
You can configure the threshold of cosine-similarity for which we consider two sentences as similar. Also, you can specify the minimal size for a local community. This allows you to get either large coarse-grained clusters or small fine-grained clusters.
We apply it on the Quora Duplicate Questions dataset and the output looks something like this:
Cluster 1, #83 Elements
What should I do to improve my English ?
What should I do to improve my spoken English?
Can I improve my English?
...
Cluster 2, #79 Elements
How can I earn money online?
How do I earn money online?
Can I earn money online?
...
...
Cluster 47, #25 Elements
What are some mind-blowing Mobile gadgets that exist that most people don't know about?
What are some mind-blowing gadgets and technologies that exist that most people don't know about?
What are some mind-blowing mobile technology tools that exist that most people don't know about?
...
Topic Modeling
Topic modeling is the process of discovering topics in a collection of documents.
An example is shown in the following picture, which shows the identified topics in the 20 newsgroup dataset:
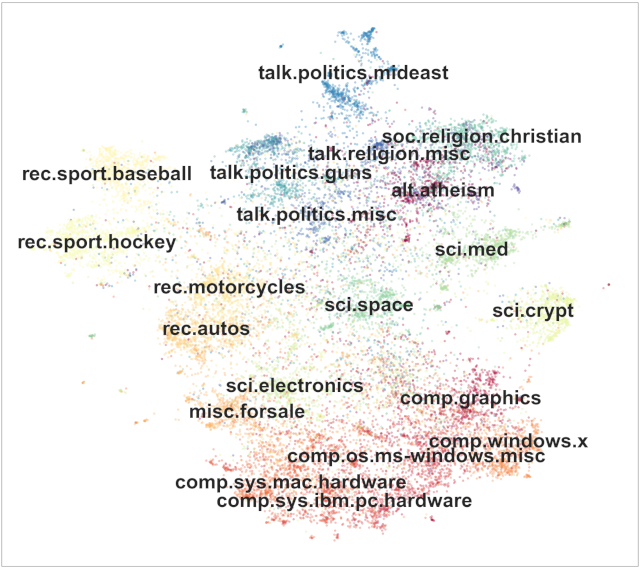
For each topic, you want to extract the words that describe this topic:

Sentence-Transformers can be used to identify these topics in a collection of sentences, paragraphs or short documents. For an excellent tutorial, see Topic Modeling with BERT as well as the BERTopic and Top2Vec repositories.
Image source: Top2Vec: Distributed Representations of Topics