MS MARCO
MS MARCO Passage Ranking is a large dataset to train models for information retrieval. It consists of about 500k real search queries from Bing search engine with the relevant text passage that answers the query.
This page shows how to train Sentence Transformer models on this dataset so that it can be used for searching text passages given queries (key words, phrases or questions).
If you are interested in how to use these models, see Application - Retrieve & Re-Rank.
There are pre-trained models available, which you can directly use without the need of training your own models. For more information, see: Pretrained Models > MSMARCO Passage Models.
Bi-Encoder
For retrieval of suitable documents from a large collection, we have to use a Sentence Transformer (a.k.a. bi-encoder) model. The documents are independently encoded into fixed-sized embeddings. A query is embedded into the same vector space. Relevant documents can then be found by using cosine similarity or dot-product.
This page describes two strategies to train an bi-encoder on the MS MARCO dataset:
MultipleNegativesRankingLoss
Training code: train_bi_encoder_mnrl.py
When we use MultipleNegativesRankingLoss, we provide triplets: (query, positive_passage, negative_passage) where positive_passage is the relevant passage to the query and negative_passage is a non-relevant passage to the query. We compute the embeddings for all queries, positive passages, and negative passages in the corpus and then optimize the following objective: The (query, positive_passage)` pair must be close in the vector space, while ``(query, negative_passage) should be distant in vector space.
To further improve the training, we use in-batch negatives:
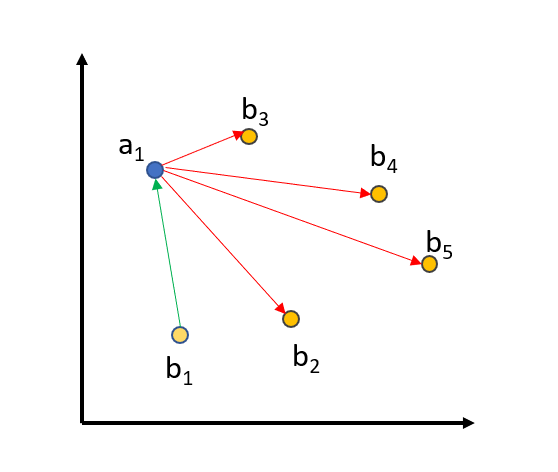
We embed all queries, positive_passages, and negative_passages into the vector space. The matching (query_i, positive_passage_i) should be close, while there should be a large distance between a query and all other (positive/negative) passages from all other triplets in a batch. For a batch size of 64, we compare a query against 64+64=128 passages, from which only one passage should be close and the 127 others should be distant in vector space.
One way to improve training is to choose really good negatives, also know as hard negative: The negative should look really similar to the positive passage, but it should not be relevant to the query.
We find these hard negatives in the following way: We use existing retrieval systems (e.g. lexical search and other bi-encoder retrieval systems), and for each query we find the most relevant passages. We then use a powerful cross-encoder/ms-marco-MiniLM-L6-v2 Cross-Encoder to score the found (query, passage) pairs. We provide scores for 160 million such pairs in our MS MARCO Mined Triplet dataset collection.
For MultipleNegativesRankingLoss, we must ensure that in the triplet (query, positive_passage, negative_passage) that the negative_passage is indeed not relevant for the query. The MS MARCO dataset is sadly highly redundant, and even though that there is on average only one passage marked as relevant for a query, it actually contains many passages that humans would consider as relevant. We must ensure that these passages are not passed as negatives: We do this by ensuring a certain threshold in the CrossEncoder scores between the relevant passages and the mined hard negative. By default, we set a threshold of 3: If the (query, positive_passage) gets a score of 9 from the CrossEncoder, than we will only consider negatives with a score below 6 from the CrossEncoder. This threshold ensures that we actually use negatives in our triplets.
You can find this data by traversing to any of the datasets in the MS MARCO Mined Triplet dataset collection and using the triplet-hard subset. Across all datasets, this refers to 175.7 million triplets. The original data can be found here. Load some of it using:
from datasets import load_dataset
train_dataset = load_dataset("sentence-transformers/msmarco-co-condenser-margin-mse-sym-mnrl-mean-v1", "triplet-hard", split="train")
# Dataset({
# features: ['query', 'positive', 'negative'],
# num_rows: 11662655
# })
print(train_dataset[0])
# {'query': 'what are the liberal arts?', 'positive': 'liberal arts. 1. the academic course of instruction at a college intended to provide general knowledge and comprising the arts, humanities, natural sciences, and social sciences, as opposed to professional or technical subjects.', 'negative': "Rather than preparing students for a specific career, liberal arts programs focus on cultural literacy and hone communication and analytical skills. They often cover various disciplines, ranging from the humanities to social sciences. 1 Program Levels in Liberal Arts: Associate degree, Bachelor's degree, Master's degree."}
MarginMSE
Training code: train_bi_encoder_margin_mse.py
MarginMSELoss is based on the paper of Hofstätter et al. Like when training with MultipleNegativesRankingLoss, we can use triplets: (query, passage1, passage2). However, in contrast to MultipleNegativesRankingLoss, passage1 and passage2 do not have to be strictly positive/negative, both can be relevant or not relevant for a given query.
We then compute the Cross-Encoder score for (query, passage1) and (query, passage2). We provide scores for 160 million such pairs in our msmarco-hard-negatives dataset. We then compute the distance: CE_distance = CEScore(query, passage1) - CEScore(query, passage2).
For our Sentence Transformer (e.g. bi-encoder) training, we encode query, passage1, and passage2 into embeddings and then measure the dot-product between (query, passage1) and (query, passage2). Again, we measure the distance: BE_distance = DotScore(query, passage1) - DotScore(query, passage2)
We then want to ensure that the distance predicted by the bi-encoder is close to the distance predicted by the cross-encoder, i.e., we optimize the mean-squared error (MSE) between CE_distance and BE_distance.
An advantage of MarginMSELoss compared to MultipleNegativesRankingLoss is that we don’t require a positive and negative passage. As mentioned before, MS MARCO is redundant and many passages contain the same or similar content. With MarginMSELoss, we can train on two relevant passages without issues: In that case, the CE_distance will be smaller and we expect that our bi-encoder also puts both passages closer in the vector space.
And disadvantage of MarginMSELoss is the slower training time: We need way more epochs to get good results. In MultipleNegativesRankingLoss, with a batch size of 64, we compare one query against 128 passages. With MarginMSELoss, we compare a query only against two passages.
MarginMSE + MultipleNegativesRanking
Training code: train_bi_encoder_margin_mse_mnrl.py
Combining MarginMSELoss with MultipleNegativesRankingLoss recovers the in-batch contrastive signal that pure MarginMSE lacks while keeping the teacher distillation. This is the recipe behind the canonical sentence-transformers/msmarco-distilbert-margin-mse-mnrl-mean-v1 family of models. Hard negatives are mined from the 13 datasets in the MS MARCO Mined Triplets collection. Both losses share a single forward pass via compute_loss_from_embeddings so peak memory is the same as a single loss. Both losses score with raw dot product to match the unnormalized embedding regime. MNRL uses similarity_fct=dot_score, scale=1.0 so it doesn’t sneak magnitude normalization back in via the default cos_sim.