MLM
Masked Language Model (MLM) is the process how BERT was pre-trained. It has been shown, that to continue MLM on your own data can improve performances (see Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks). In our TSDAE-paper we also show that MLM is a powerful pre-training strategy for learning sentence embeddings. This is especially the case when you work on some specialized domain.
Note: Only running MLM will not yield good sentence embeddings. But you can first tune your favorite transformer model with MLM on your domain specific data. Then you can fine-tune the model with the labeled data you have or using other data sets like NLI, Paraphrases, or STS.
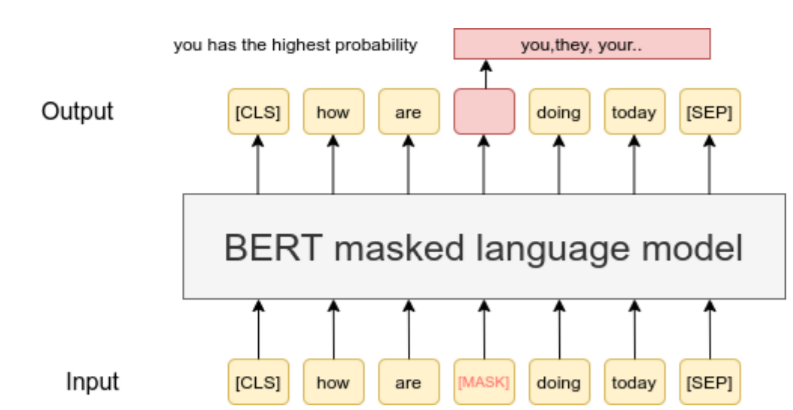
Running MLM
The train_mlm.py script provides an easy option to run MLM on your data. You run this script by:
python train_mlm.py distilbert-base path/train.txt
You can also provide an optional dev dataset:
python train_mlm.py distilbert-base path/train.txt path/dev.txt
Each line in train.txt / dev.txt is interpreted as one input for the transformer network, i.e. as one sentence or paragraph.
For more information how to run MLM with huggingface transformers, see the Language model training examples.