TSDAE¶
This section shows an example, of how we can train an unsupervised TSDAE (Transformer-based Denoising AutoEncoder) model with pure sentences as training data.
Background¶
During training, TSDAE encodes damaged sentences into fixed-sized vectors and requires the decoder to reconstruct the original sentences from these sentence embeddings. For good reconstruction quality, the semantics must be captured well in the sentence embeddings from the encoder. Later, at inference, we only use the encoder for creating sentence embeddings. The architecture is illustrated in the figure below:
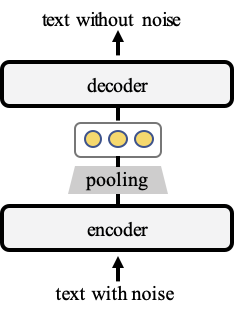
Unsupervised Training with TSDAE¶
Training with TSDAE is simple. You just need a set of sentences:
from sentence_transformers import SentenceTransformer, LoggingHandler
from sentence_transformers import models, util, datasets, evaluation, losses
from torch.utils.data import DataLoader
# Define your sentence transformer model using CLS pooling
model_name = "bert-base-uncased"
word_embedding_model = models.Transformer(model_name)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(), "cls")
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# Define a list with sentences (1k - 100k sentences)
train_sentences = [
"Your set of sentences",
"Model will automatically add the noise",
"And re-construct it",
"You should provide at least 1k sentences",
]
# Create the special denoising dataset that adds noise on-the-fly
train_dataset = datasets.DenoisingAutoEncoderDataset(train_sentences)
# DataLoader to batch your data
train_dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
# Use the denoising auto-encoder loss
train_loss = losses.DenoisingAutoEncoderLoss(
model, decoder_name_or_path=model_name, tie_encoder_decoder=True
)
# Call the fit method
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=1,
weight_decay=0,
scheduler="constantlr",
optimizer_params={"lr": 3e-5},
show_progress_bar=True,
)
model.save("output/tsdae-model")
TSDAE from Sentences File¶
train_tsdae_from_file.py loads sentences from a provided text file. It is expected, that the there is one sentence per line in that text file.
TSDAE will be training using these sentences. Checkpoints are stored every 500 steps to the output folder.
TSDAE on AskUbuntu Dataset¶
The AskUbuntu dataset is a manually annotated dataset for the AskUbuntu forum. For 400 questions, experts annotated for each question 20 other questions if they are related or not. The questions are split into train & development set.
train_askubuntu_tsdae.py - Shows an example how to train a model on AskUbuntu using only sentences without any labels. As sentences, we use the titles that are not used in the dev / test set.
| Model | MAP-Score on test set |
|---|---|
| TSDAE (bert-base-uncased) | 59.4 |
| pretrained SentenceTransformer models | |
| nli-bert-base | 50.7 |
| paraphrase-distilroberta-base-v1 | 54.8 |
| stsb-roberta-large | 54.6 |
TSDAE as Pre-Training Task¶
As we show in our TSDAE paper, TSDAE also a powerful pre-training method outperforming the classical Mask Language Model (MLM) pre-training task.
You first train your model with the TSDAE loss. After you have trained for a certain number of steps / after the model converges, you can further fine-tune your pre-trained model like any other SentenceTransformer model.
Citation¶
If you use the code for augmented sbert, feel free to cite our publication TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning:
@article{wang-2021-TSDAE,
title = "TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning",
author = "Wang, Kexin and Reimers, Nils and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2104.06979",
month = "4",
year = "2021",
url = "https://arxiv.org/abs/2104.06979",
}